논문 리뷰 (1) - Bayesian Time Series Forecasting with Change Point and Anomaly Detection
06 Aug 2022
Reading time ~4 minutes
개요
운영 중인 IT 시스템의 이상 징후를 실시간으로 탐지하고 미래 부하를 예측하는 AI 모니터링 소프트웨어를 개발하고 있다. 시스템의 상태를 나타내는 정보들은 매우 다양하다. Oracle Database 같은 경우는 수치만 이용해도 30개 이상을 사용할 수 있고, 이벤트까지 합치면 수백 개가 넘어간다. 그만큼 다양한 데이터들이 있으므로, 이들이 나타내는 패턴도 매우 다양하다. 쌍봉 형태의 분포를 보이면서 진동하는 패턴, 계단 형태의 패턴, 일정하게 진동하다가 스파이크처럼 순간적으로 크게 튀는 패턴, 증가하다가 어느 시점에서 확 떨어지는 번개 모양 패턴 등등이 있다.
이 논문에서는 이상치 탐지 및 변경점 탐지를 수행하면서 시계열을 예측하는 베이지안 상태 공간 모형을 제안했다. Neural Network가 비선형 시계열을 잘 예측하는 것은 사실이지만 Back Propagation 할 때 이상치가 제거되지 않으면 이로 인한 오차가 그대로 Weight에 영향을 미치므로, 이상치 제거는 데이터 전처리에서 필요한 작업이다. 실제 고객사 데이터에서도 장애가 아닌데 값이 높게 튀는 이상치들이 많고 이들이 잘 제거되지 않았을 때, Deep Neural Network의 예측값이 발산하는 것을 본 적도 있다. 그렇기 때문에, 이상치와 변경점을 탐지하면서 예측하는 위의 논문이 성능을 향상시킬 수 있을 것으로 보여 읽게 됐다. 설령 예측 성능이 좋지 않거나 리소스를 많이 사용해서 사용하지 않더라도, 논문에서 활용한 이상치 탐지 및 변경점 탐지법은 다른 모든 기능들에도 전처리 모듈로 적용할 수 있을 것으로 보인다.
핵심 용어
Bernoulli Distribution, Normal Distribution, Likelihood Function, Convergence, Prior Distribution, Posterior Distribution, Metropolis-Hastings, Gibbs-Sampler, State Space Model, Kalman Filter, Fake-path trick
시계열 성분 분해
관측된 시계열 데이터는 여러 방식으로 모델링 될 수 있다. Random Walk 형태로 표현될 수도 있고, (S)AR(I)MA 같은 선형 확률 과정 형태로 표현될 수도 있다. 그 중 시계열 성분 분해는 관측된 시계열이 트렌드, 계절성, 그 외 나머지의 형태로 표현하는 방법이다. 트렌드는 장기적인 흐름을 말하며, 계절성은 주기를 가지고 반복되는 패턴을 말한다. 예를 들어 아이스크림 판매량은 더운 날에 많이 팔리고 추운 날에 덜 팔린다고 기대할 수 있으므로, 트렌드는 증감을 반복할 것이고 계절성은 1년 주기의 sin, cos의 합이라 가정하고 수식을 세울 수 있다.
\(Y(t) = T(t) + S(t) + R(t) \quad\) \(where\) \(T(t) = \mu, \quad S(t) = sin(2\pi ft) + cos(2\pi ft), \quad R(t) =\epsilon_{t}\)
논문 저자들은 성분 분해를 조금 더 확장시켜서, 트렌드와 계절성 그리고 나머지 항 이외에 Change Point와 Anomaly Point까지 추가했다.
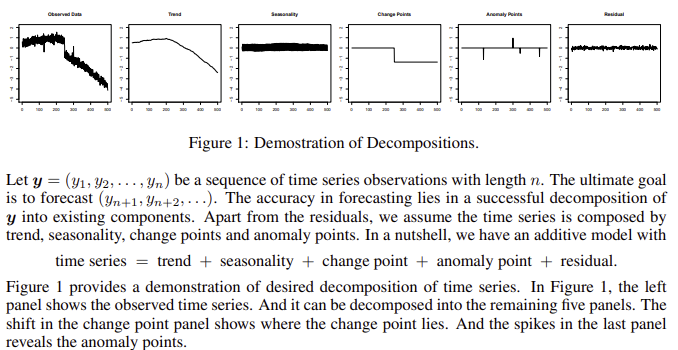
즉, 관측된 시계열은 다섯 가지 성분들의 함수로 가정한다. 대문자들은 Trend, Seasonality, Anomaly Point, Change Point, Remainder이고, 이들과 시계열 사이의 어떤 관계를 f로 표시했다.
\[Y(t) = f(T(t), S(t), A(t), C(t), R(t))\]여기서 함수 f가 바로 모델이 된다. 그렇다면, 함수 f를 어떻게 설정해야 할까?
Model Overview
단순한 모형부터 시작해서 모델을 발전시켜보자. 먼저, 시계열이 평균 근처에서 진동하는 형태라고 가정해보자. 그렇다면, 다음과 같아진다.
\[Y(t) = \mu + \sigma^{2}\]평균은 \(\mu\), 진동은 \(\sigma^{2}\)으로 표시했다. 자, 이 모형이 타당한가?
그렇지 않다. IT 시스템은 부하량에 따라 계속 상태가 바뀌므로 평균도 시간이 지나면서 변동하게 된다. 그리고 계절성이 모형에 존재하지 않는다. 따라서, 시간 정보와 계절성을 추가하자.
\[Y(t) = \mu_{t} + \gamma_{t} + \sigma^{2}\]계절성은 \(\gamma\)로 표시했다. 자, 이 모형은 타당한가?
그렇지 않다. 현재 시점의 평균은 보통 이전 시점의 영향을 받게 된다. 예를 들어, 메모리 사용량은 누수가 발생하면 이전 시점과 동일하거나 값이 커진다. 따라서, 평균 사이의 관계를 추가해줘야 한다.
\[Y(t) = \mu_{t} + \gamma_{t} + \sigma_{y}^{2}\] \[\mu_{t} = \mu_{t-1} + \delta_{t} + \sigma_{\mu}^{2}\]이제 모형은 두 가지 식으로 구성된다. 평균 사이의 관계는 \(\delta\)로 표시했다. 자, 모형은 이제 타당한가?
그렇지 않다. 먼저, Anomaly Point와 Change Point가 없다. 이들은 데이터에 내재된 일반적인 Random Noise보다 보통 훨씬 크게 변화하므로, 다른 형태의 변동을 가져야 한다. 그리고 Seasonality도 정의에 의해서 일정한 주기를 가지는 성분이므로, Seasonality 사이의 관계가 있다. 따라서, 이들을 추가하면 식은 다음과 같아진다.
\[Y(t) = \mu_{t} + \gamma_{t} + \begin{cases} \epsilon_{t}, \quad if \quad not \quad anomaly\\ o_{t}, \quad if \quad anomaly \end{cases}\] \[\mu_{t} = \mu_{t-1} + \delta_{t} + \begin{cases} u_{t}, \quad if \quad not \quad change \quad point \\ r_{t}, \quad if \quad change \quad point \end{cases}\] \[\gamma_{t} = -\sum_{s=1}^{S-1}\gamma_{t-s} + w_{t}\]모형은 이제 타당한가?
대부분의 성분을 모델에 포함했다. 하지만, 다른 성분들도 변하는 만큼 slope를 의미하는 \(\delta\) 에도 관계가 있다고 보는 게 자연스럽다. 이를 추가하자.
\[Y(t) = \mu_{t} + \gamma_{t} + \begin{cases} \epsilon_{t}, \quad if \quad not \quad anomaly\\ o_{t}, \quad if \quad anomaly \end{cases}\] \[\mu_{t} = \mu_{t-1} + \delta_{t} + \begin{cases} u_{t}, \quad if \quad not \quad change \quad point \\ r_{t}, \quad if \quad change \quad point \end{cases}\] \[\gamma_{t} = -\sum_{s=1}^{S-1}\gamma_{t-s} + w_{t}\] \[\delta_{t} = \delta_{t-1} + v_{t}\]마지막으로 생각해보자. 트렌드와 계절성 모두 추가했고 변경점과 이상치도 추가했으며 이들 사이의 관계도 정의했으므로, 모델은 적절해보인다. 따라서, 위의 모델을 최종적으로 사용하면 될 것 같다.
State Space Model
생각을 추가하니, 모형이 복잡해졌다. 모형을 살펴보면, 우리가 관측할 수 있는 시계열은 관측할 수 없는 잠재 변수들로 구성되어 있는 것을 알 수 있다. 이러한 모형을 상태 공간 모형이라고 한다. 즉, 시계열이 관측할 수 없는 어떤 잠재 변수들에 영향을 받는다고 가정한다. 여기서 말하는 잠재 변수들이 상태 변수가 된다. 이 상태 변수들과 시계열 사이의 관계를 포착할 수 있으면, 상태 변수들의 변화에 따라서 시계열이 어떻게 변할 지 예측할 수 있다.
ARIMA를 포함한 선형 확률 과정과 비교해보자. 선형 확률 과정의 파라미터는 fitting을 하면 값이 고정되는 static model이지만, 상태 공간 모형은 상태 변수들이 시간이 지나면서 계속 변하는 dynamic model이므로, 아래와 같은 특성을 가지는 시계열을 처리할 때 유용하다.
- non-stationary 데이터
- 시간에 따라 파라미터가 변하는 게 타당한 시계열
- 시계열에 영향을 미치는 어떤 다른 변수들이 있을 때
즉, 대부분의 현실에서 만나는 시계열들을 다룰 때 유용하게 쓰일 수 있다.
상태 공간 모형은 크게 두 가지 요소로 구성된다. 잠재 변수 사이의 관계식(transition equation)과 잠재 변수와 시계열 사이의 관계식(observation equation)이다. 상태 공간 모형에 대해서는 칼만 필터와 함께 다음 포스팅에서 조금 더 자세히 알아보겠다.